
По аналогии с DevOps и DataOps, в связи с популяризацией методов Machine Learning и ростом их практических внедрений, у бизнеса появилась потребность в организации непрерывного сотрудничества и взаимодействия между всеми участниками процессов работы с моделями машинного обучения от бизнеса до инженеров и разработчиков Big Data, включая Data Scientist’ов и ML-специалистов. Понятие MLOps еще достаточно молодое, однако с каждым днем оно становится все более востребованным. Впервые о необходимости комплексного управления жизненным циклом машинного обучения в промышленной эксплуатации (production) профессиональное сообщество публично заговорило примерно в 2018 году, после одной из презентаций Google [1].
На практике проблема внедрения ML-моделей в реальный бизнес не исчерпывается подготовкой данных, разработкой и обучением нейросети или другого алгоритма Machine Learning. На качество production-решения влияет множество факторов, от верификации датасетов до тестирования и развертывания в производственной среде в виде надежного Big Data приложения. Это означает, что реальные результаты прогнозирования или классификации зависят не только от нейросетевой архитектуры и того метода машинного обучения, который предложил Data Scientist, но и от того, как команда разработчиков реализовала данную модель, а администраторы развернули ее в кластерном окружении. Также имеет значение качество входных данных (Data Quality), источники, каналы и периодичность их поступления, что относится к области ответственности дата-инженера. Организационные и технические препятствия при взаимодействии разнопрофильных специалистов, задействованных в разработке, тестировании, развертывании и поддержке ML-решений приводят к увеличению сроков создания продукта и снижению его ценности для бизнеса. Для устранения таких барьеров и придумана концепция MLOps, которая, подобно DevOps и DataOps, стремится увеличить автоматизацию и улучшить качество промышленных ML-решений, уделяя внимание нормативным требованиям и выгоде для бизнеса [2].
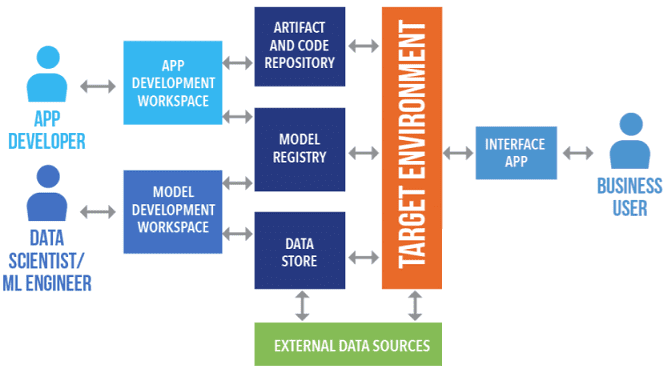
Таким образом, MLOps – это культура и набор практик комплексного и автоматизированного управления жизненным циклом систем машинного обучения, объединяющие их разработку (Development) и операции эксплуатационного сопровождения (Operations), в т.ч. интеграцию, тестирование, выпуск, развертывание и управление инфраструктурой. Можно сказать, что MLOps расширяет методологию CRISP-DM с помощью Agile-подхода и технических инструментов автоматизированного выполнения операций с данными, ML-моделями, кодом и окружением. К таким средствам можно отнести, например, Cloudera Data Science Workbench. Ожидается, что применение MLOps на практике позволит избежать распространенных ошибок и проблем, с которыми сталкиваются Data Scientist’ы, работающие в соответствие с классическими фазами CRISP-DM. О других плюсах, которые дает эта концепция бизнесу, мы поговорим далее.
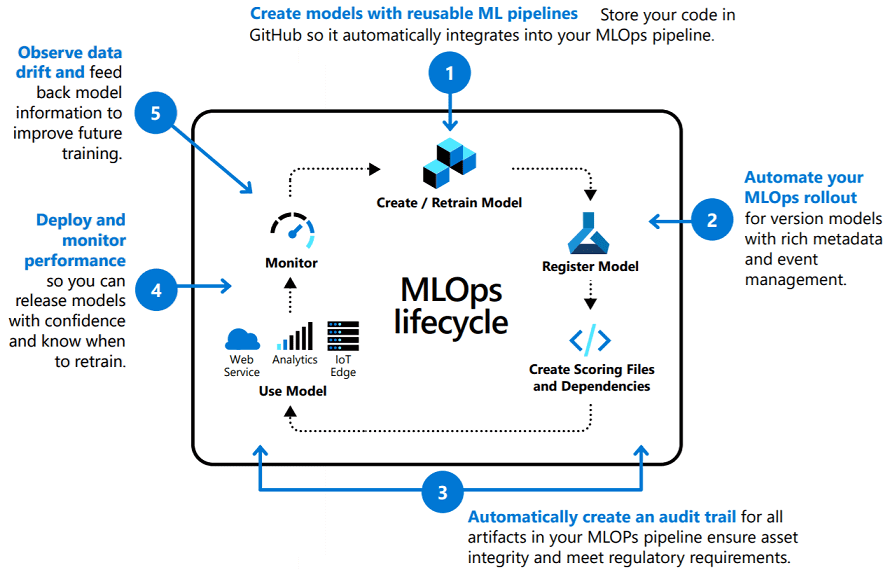
10 ГЛАВНЫХ ПРЕИМУЩЕСТВ ДЛЯ БИЗНЕСА И DATA SCIENCE
Из всех выгод внедрения MLOps наиболее значимыми считаются следующие преимущества Agile-подходов применительно к специфике промышленного развертывания Machine Learning [3]:
- сокращение сроков получения качественных результатов за счет надежного и эффективного управления жизненным циклом машинного обучения;
- воспроизводимые рабочие процессы и модели благодаря методам и средствам Continuous Development/Integration/Training (CI/CD/CT);
- простота развертывания высокоточных ML-моделей в любом месте и в любое время;
- система комплексного управления и непрерывного контроля ресурсов машинного обучения;
- устранение организационных барьеров и объединение опыта разнопрофильных ML-специалистов.
Таким образом, с помощью MLOps можно оптимизировать следующие аспекты ML-операций [2]:
- унифицировать цикл выпуска моделей машинного обучения и созданных на их основе программных продуктов;
- автоматизировать тестирование артефактов Machine Learning, таких как проверка данных, тестирование самой ML-модели и ее интеграции в production-решение;
- внедрить гибкие принципы в проекты машинного обучения;
- поддерживать модели машинного обучения и наборы данных для их в системах CI/CD/CT;
- сократить технический долг по ML-моделям.
Примечательно, что организационные приемы MLOps должны быть независимыми от языка, фреймворка, платформы и инфраструктуры. А с технической точки зрения общая архитектура MLOps-системы будет включать в себя платформы для сбора и агрегации Big Data, приложения анализа и подготовки данных к ML-моделированию, средства для выполнения вычисления и аналитики, а также инструменты для автоматизированного перемещения моделей Machine Learning, данных и созданных на их основе программных продуктов между различными процессами их жизненного цикла [1]. Это позволит частично или полностью автоматизировать рабочие задачи Data Scientist’a, дата-инженера, ML-специалиста, архитектора и разработчика Big Data решений, а также DevOps-инженера с помощью унифицированных и эффективных конвейеров (pipelines).
Источники