
Конвейеры – это простой способ упорядочить код предварительной обработки данных и ML-моделирования. Непрерывная цепочка связанных работ дает следующие преимущества в промышленном Machine Learning:
- чистый код за счет автоматизации процедур подготовки данных – выборка, очистка, генерация предикторов (фичей, от англ. feature) и пр.;
- сокращение ошибок благодаря отработанной последовательности шагов, не получится пропустить или неправильно выполнить какой-то этап;
- простота развертывания в production – обычно преобразовать ML-модель от прототипа к масштабируемому и надежному решению для промышленной эксплуатации достаточно сложно, однако конвейеры помогут и здесь, облегчая тестирование и прочие MLOps-процедуры;
- дополнительная проверка ML-модели – можно применить перекрестную проверку (кросс-валидацию) и другие методы к этапам конвейера, пробуя различные параметры. Это ускоряет оптимизацию алгоритма и выбор наилучших конфигурационных настроек.
В конвейер могут входить следующие процедуры подготовки данных к машинному обучению и собственно само ML-моделирование:
- формирование выборки;
- устранение пропусков;
- преобразование категориальных значений в номинальные и числовые;
- нормализация диапазона значений для каждого измерения;
- наконец, непосредственно ML-моделирование, где обучается алгоритм машинного обучения.
Таким образом, можно объединить весь поток обработки данных в один конвейер, и использовать его в дальнейшем, в соответствии с идеями MLOps. Конвейер как ML-алгоритм включает следующие методы [1]:
- fit(), который начинает обучение;
- score(), который возвращает предсказанное значение;
- evaluate() для оценки производительности модели по валидационным данным.

Далее мы рассмотрим, как эти методы построения ML-конвейеров работают в Apache Spark.
ИЗ ЧЕГО СОСТОИТ ML-PIPELINE В APACHE SPARK
Apache Spark 3.0 воплощает идею конвейеров машинного обучения, предоставляя единый набор высокоуровневых API-интерфейсов на основе DataFrame, которые помогают пользователям создавать и настраивать ML-pipeline’ы. Инструмент машинного обучения Apache Spark, библиотека MLlib стандартизирует API-интерфейсы для ML-алгоритмов, чтобы упростить объединение нескольких алгоритмов в один конвейер или рабочий процесс. Это реализовано с помощью следующих специальных структур данных и методов [2]:
- DataFrame – ML API, который использует DataFrame из Spark SQL в качестве датасета для машинного обучения, который может содержать различные типы данных, включая специфические для Machine Learning. Например, DataFrame может иметь разные столбцы, в которых хранятся текст, векторы признаков, метки и прогнозы.
- Преобразователь (Transformer) – алгоритм, который может преобразовывать один DataFrame в другой. Например, ML-модель – это трансформер, который преобразует DataFrame с предикторами (фичами) в DataFrame с прогнозами. Трансформер можно представить в виде абстракции, которая включает преобразователи фичей и обученные модели. Технически Transformer реализует метод transform(), который преобразует один DataFrame в другой путем добавления одного или нескольких столбцов. К примеру, VectorAssembler является преобразователем, поскольку он принимает входный датафрейм и возвращает преобразованный с новым столбцом, который является векторным представлением всех функций [3].

- Оценщик (Estimator) – алгоритм, который можно разместить в DataFrame для создания преобразователя. Например, алгоритм обучения – это оценщик, который обучается на DataFrame и создает ML-модель. Можно сказать, что оценщик – это высокоуровневая абстракция алгоритма обучения, который возвращает модель (преобразователь). Она, в свою очередь, преобразует датафрейм в соответствии с параметрами, которые исследуются на этапе подгонки (fitting) или обучения. Технически каждый оценщик реализует метод fit(), принимающий DataFrame и создающий ML-модель, которая имеет метод transform(). Например, алгоритм обучения LogisticRegression, является оценщиком, который возвращает преобразователь LogisticRegresionModel после исследования параметров данных [3].
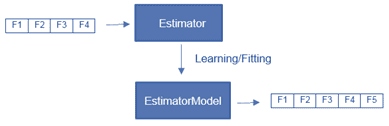
- Конвейер (Pipeline), который связывает несколько преобразователей и оценщиков в единый рабочий процесс машинного обучения. Apache Spark предоставляет класс, который формируется путем объединения различных этапов конвейера, т.е. Estimator’ов и Transformer’ов, выполняемых последовательно. В классе конвейера есть метод fit(), который запускает весь рабочий процесс. Он возвращает модель PipelineModel, которая имеет точно такое же количество этапов, что и конвейер, за исключением того, что все этапы оценщика заменяются соответствующим преобразователем, полученным во время выполнения. Эта модель конвейера может быть сериализована для повторного использования без затрат на настройку или обучение. Во время выполнения каждый этап вызывается последовательно, в зависимости от его типа (преобразователь или оценщик) вызываются соответствующие методы fit() или transform().
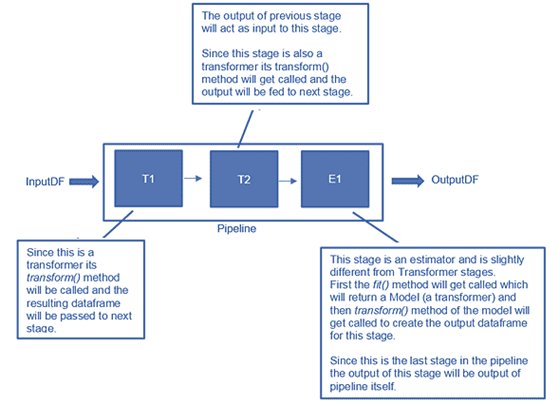
- Параметр (Parameter) для задания настроечных параметров у преобразователей и оценщиков через общий API. Каждый экземпляр преобразователя или оценщика имеет уникальный идентификатор, который полезен при указании параметров.
Примечательно, что методы Transformer.transform() и Estimator.fit() не имеют состояния. В перспективе алгоритмы с отслеживанием состояния будут поддерживаться с помощью альтернативных концепций [2].
ПРИМЕР КОНВЕЙЕРА МАШИННОГО ОБУЧЕНИЯ В SPARK MLLIB
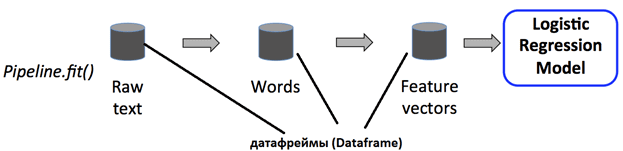
Конвейер определяется как последовательность этапов, каждый из которых является преобразователем или оценщиком. Эти этапы выполняются по порядку, преобразуя входной DataFrame по мере выполнения каждого этапа. Для шагов Transformer в API DataFrame вызывается метод transform(). Estimator’ы используют метод fit() для создания трансформеров, которые, в свою очередь, становятся частью конвейерной модели. Чтобы наглядно проиллюстрировать это, рассмотрим простой пример конвейера машинного обучения в Apache Spark из 3-х этапов [2]:
- преобразователями являются Tokenizer и HashingTF, а LogisticRegression – оценщик;

- метод fit() вызывается в исходном DataFrame, который содержит необработанные текстовые документы и метки;
- метод transform() разбивает необработанные текстовые документы на слова, добавляя новый столбец со словами в DataFrame;
- метод transform() преобразует столбец слов в векторы признаков, добавляя новый столбец с этими векторами в DataFrame.
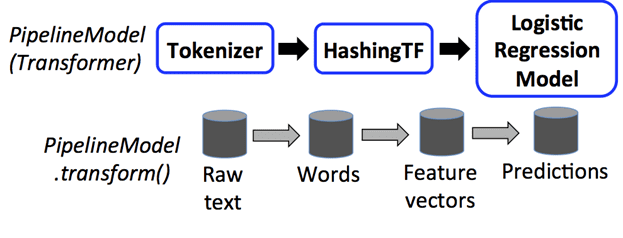
- поскольку LogisticRegression является оценщиком, конвейер сначала вызывает fit() для создания LogisticRegressionModel. Если бы у конвейера было больше оценщиков, он вызвал бы метод transform() LogisticRegressionModel в DataFrame перед передачей DataFrame на следующий этап.
Конвейер – это оценщик: после запуска метода fit()он создает модель PipelineModel, которая является преобразователем. Эта PipelineModel используется во время тестирования и состоит из того же количества этапов, что и исходный конвейер. При этом все оценщики исходного конвейера стали преобразователями. Когда метод transform() модели PipelineModel вызывается для тестового датасета, данные передаются через соответствующий конвейер по порядку. Метод transform() каждого этапа обновляет датасет и передает его на следующий этап. Таким образом, Pipelines и PipelineModels помогают гарантировать, что данные обучения и тестирования проходят одинаковые этапы обработки фичей.
ОСОБЕННОСТИ ПОСТРОЕНИЯ КОНВЕЙЕРОВ МАШИННОГО ОБУЧЕНИЯ В СПАРК
При практическом использовании идеи ML-конвейеров в Apache Spark, следует помнить о некоторых особенностях или ограничениях этого фреймворка [2]:
- этапы конвейера указываются в виде упорядоченного массива. Обычно конвейер имеет линейную структуру, где этапы выполняются друг за другом, т.е. последовательно, когда каждый этап использует результаты предыдущего. Однако, можно создавать и нелинейные конвейеры, где поток данных представлен в виде DAG-графа (направленный ациклический граф, Direct Acyclic Graph). В Apache Spark это определяется неявно на основе имен входных и выходных столбцов каждого этапа, обычно указываемых как параметры. Если конвейер формирует DAG, этапы должны быть указаны в топологическом порядке.
- этапы конвейера должны быть уникальными экземплярами с оригинальными идентификаторами. Однако, разные экземпляры преобразователей или оценщиков одного типа можно без проблем объединять в один конвейер.
- поскольку конвейеры могут обрабатывать DataFrame’ы различных типов, их проверка во время компиляции невозможна. Вместо этого Pipeline и PipelineModel выполняют runtime-проверку типов данных перед фактическим запуском конвейера. Эта реализуется с использованием схемы датафрейма, описания типов данных столбцов.
- чтобы сохранить модель или конвейер на диск для дальнейшего использования, в API Dataframe ml и pyspark.ml, начиная с версии 2.3, добавлены соответствующие возможности для Scala, Java и Python. Пока язык R использует другой формат, поэтому модели, сохраненные в R, можно загрузить обратно только в R, в будущем это будет исправлено. В общем, Spark MLlib поддерживает обратную совместимость: сохранив ML-модель или конвейер в одной версии фреймворка, ее можно загрузить снова и использовать в следующем релизе. Однако, бывают редкие исключения, связанные с особенностями мажорных и минорных обновлений.
Посмотреть реализацию ML-pipeliene’ов в Apache Spark MLLib с примерами кода на Scala, Java и Python можно в дополнительных источниках [1, 2, 3].
Источники